1. Transformer#
1.1 背景#
传统序列建模主要依赖 RNN/LSTM 或 CNN,但这类方法存在无法并行、长距离依赖难学习的问题。
Transformer的创新点是完全舍弃循环和卷积,完全基于注意力机制来建模序列关系。对比如下图所示: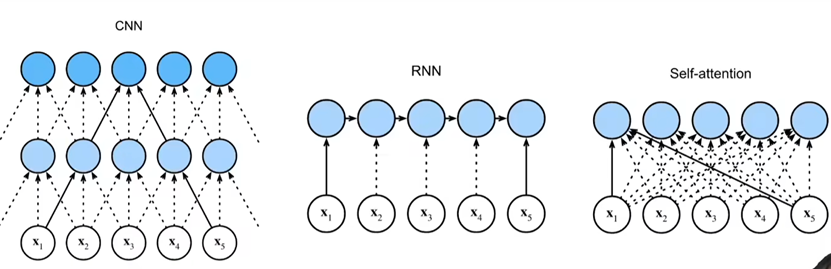
1.2 模型核心思想#
模型结构如下图所示: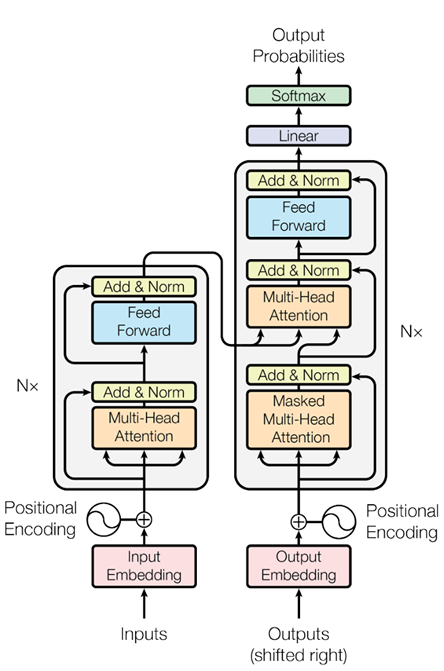
自注意力 (Self-Attention):序列中的每个位置都可以直接关注到任意位置,不受距离限制。
缩放点积注意力 (Scaled Dot-Product Attention):通过 Query-Key-Value 机制计算注意力权重。
多头注意力 (Multi-Head Attention):多个子空间并行关注不同的信息,提高模型表达能力。
位置编码 (Positional Encoding):因为没有卷积和循环,所以通过正弦/余弦函数引入位置信息。
编码器-解码器结构:和传统 Seq2Seq 类似,但内部完全由注意力 + 前馈网络构成。
1.3 实验结果#
在 WMT 2014 英德翻译任务上,Transformer (big) 模型取得 28.4 BLEU,比当时最好的结果高出 2 BLEU。
在英法翻译任务上,达到 41.8 BLEU,刷新单模型最优结果。
训练速度更快:仅用 8 块 P100 GPU 训练 3.5 天,比之前的 RNN/CNN 模型训练成本低得多。
1.4 优势总结#
高并行度:相比 RNN 串行计算,Transformer 可以大幅并行化。
长距离建模能力强:任何位置之间只需常数步数即可建立依赖关系。
更好的效果 & 更低的训练成本:既提高了 BLEU 分数,又缩短了训练时间。
1.5 代码#
# -*- codeing = utf-8 -*-
import math
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
from transformer_utils import Encoder, MultiHeadAttention, PositionalEncoding, AttentionDecoder, EncoderDecoder, train_seq2seq, predict_seq2seq, bleu
# 基于位置的前馈神经网络
class PositionWiseFFN(nn.Module):
"""基于位置的前馈网络"""
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,
**kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))
# 使用残差连接和层规范化
class AddNorm(nn.Module):
"""残差连接后进行层规范化"""
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X)
# 实现编码器中的一个层
class EncoderBlock(nn.Module):
"""Transformer编码器块"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, use_bias=False, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout,
use_bias)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(
ffn_num_input, ffn_num_hiddens, num_hiddens)
self.addnorm2 = AddNorm(norm_shape, dropout)
def forward(self, X, valid_lens):
Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))
return self.addnorm2(Y, self.ffn(Y))
# Transformer编码器
class TransformerEncoder(Encoder):
"""Transformer编码器"""
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, use_bias=False, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block"+str(i),
EncoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, use_bias))
def forward(self, X, valid_lens, *args):
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self.attention_weights = [None] * len(self.blks)
for i, blk in enumerate(self.blks):
X = blk(X, valid_lens)
self.attention_weights[i] = blk.attention.attention.attention_weights
return X
# Transformer解码器也是由多个相同的层组成
class DecoderBlock(nn.Module):
"""解码器中第i个块"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, i, **kwargs):
super(DecoderBlock, self).__init__(**kwargs)
self.i = i
self.attention1 = MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.attention2 = MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout)
self.addnorm2 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,
num_hiddens)
self.addnorm3 = AddNorm(norm_shape, dropout)
def forward(self, X, state):
enc_outputs, enc_valid_lens = state[0], state[1]
if state[2][self.i] is None: # 开始时为空,K、V为当前的输入X
key_values = X
else: # 后面随着预测会产生新的K、V,需要将其与之前的X concat在一起(预测阶段)
key_values = torch.cat((state[2][self.i], X), axis=1)
state[2][self.i] = key_values # 最终state[2][self.i]存储的当前计算时所有的K、V
if self.training:
batch_size, num_steps, _ = X.shape # 如果在训练阶段,需要使用masked_multi_head attention
dec_valid_lens = torch.arange(
1, num_steps + 1, device=X.device).repeat(batch_size, 1)
else: # 预测阶段则不需要使用masked_multi_head attention
dec_valid_lens = None
X2 = self.attention1(X, key_values, key_values, dec_valid_lens) # 注意此处为自注意力机制,K和V由编码器输入以及之后的预测提供,此处dec_valid_lens表示在训练阶段在预测第t个词的时候只看前面t-1个词
Y = self.addnorm1(X, X2)
Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens) # 此处为普通的注意力机制,其K和V由解码器的输出提供,此处enc_valid_lens表示最终会去除每个句子中的pad
Z = self.addnorm2(Y, Y2)
return self.addnorm3(Z, self.ffn(Z)), state
# Transformer解码器
class TransformerDecoder(AttentionDecoder):
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, **kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block"+str(i),
DecoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, i))
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
return [enc_outputs, enc_valid_lens, [None] * self.num_layers]
def forward(self, X, state):
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self._attention_weights = [[None] * len(self.blks) for _ in range (2)]
for i, blk in enumerate(self.blks):
X, state = blk(X, state)
self._attention_weights[0][i] = blk.attention1.attention.attention_weights
self._attention_weights[1][i] = blk.attention2.attention.attention_weights
return self.dense(X), state
@property
def attention_weights(self):
return self._attention_weights详细代码见本地 d2l-zh-pytorch/chapter_attention_mechanisms。
2. BERT#
2.1 背景#
传统 NLP 模型(RNN、CNN、甚至早期 Transformer)大多是任务专用的,需要针对不同任务单独训练。
当时的预训练方法(如 word2vec、ELMo)要么是静态词向量,要么是单向语言模型(GPT),不能充分利用上下文信息。
BERT 提出了一种基于 Transformer 的双向预训练模型,大幅提升 NLP 各类任务的效果。
2.2 模型核心思想#
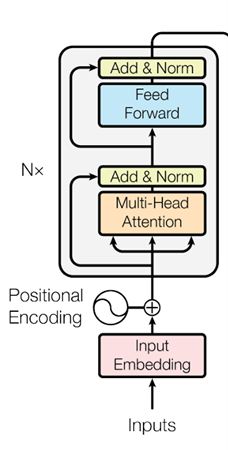
基于 Transformer Encoder:不同于 Transformer 的 Encoder-Decoder 结构,BERT 仅使用 Encoder 堆叠。
BERTBASE:num_blocks=12, num_hiddens=768, head=12 总参数量:110M
BERTLARGE num_blocks=24, num_hiddens=1024, head=16 总参数量:340M
双向上下文建模:相比 GPT(单向)、ELMo(前后两向拼接),BERT 通过 Masked LM 训练,实现真正的双向理解。
模型网络结构如下所示: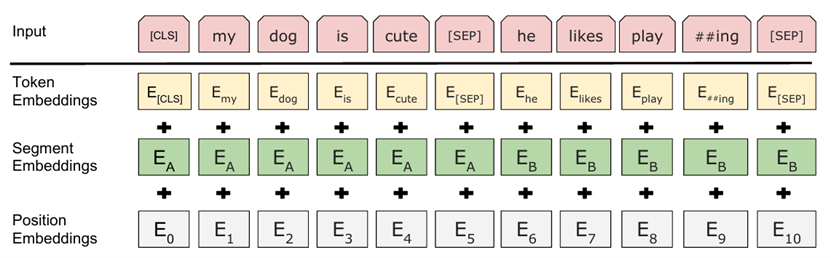
2.3 两个关键预训练任务#
2.3.1 Masked Language Model (MLM)#
(1) 训练思路:从输入句子中随机挑选 15% 的词,作为预测目标。
(2) 对这些词的处理方式:
80% 的概率替换成 [MASK](如 I love dogs → I [MASK] dogs)。
10% 的概率替换成 随机词(如 I love dogs → I apple dogs)。
10% 的概率保持原词不变(但仍然需要预测)。
模型需要根据上下文预测被遮蔽位置的词。
(3) 训练数据
Wikipedia(英文维基百科,约 25 亿词)
BookCorpus(约 8 亿词)
输入是原始文本(无人工标注,自监督),只需随机遮掩词即可构造训练样本。让模型学习到双向语境的表示。
2.3.2 Next Sentence Prediction (NSP)#
(1) 训练思路:
输入由两个句子(A, B)组成,模型需要预测 B 是否是 A 的真实后续句子。
(2) 构造方法:
50% 的情况:B 是 A 在语料中的真实下一句(标记为 IsNext)。
50% 的情况:B 是从语料中随机采样的句子(标记为 NotNext)。
模型通过 [CLS] 位置的向量做二分类任务。
(3) 训练数据:
同样来自 Wikipedia + BookCorpus。
不需要额外人工标注,只需从原始语料中拼接句子对,就能自动生成正负样本。二分类标号(IsNext / NotNext)。
让模型具备理解句子关系的能力。
2.4 实验结果#
在 11 个 NLP 任务(GLUE、SQuAD、SWAG 等)上,BERT 大幅刷新了 SOTA。
SQuAD 1.1 问答任务上,BERT 超过了人类基线。
BERT 也推动了后续一系列模型的发展(RoBERTa、ALBERT、ERNIE 等)。
2.5 优势总结#
统一框架:只需预训练一次,微调时稍加修改即可应用于不同下游任务。
强大的效果:显著提升了文本分类、问答、自然语言推理等任务的性能。
里程碑意义:BERT 开启了预训练语言模型时代,对 NLP 影响深远。
2.6 代码#
import torch
from torch import nn
from bert_utils import EncoderBlock
class BERTEncoder(nn.Module):
"""BERT编码器"""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout, max_len=1000,
key_size=768, query_size=768, value_size=768, use_bias=True):
super(BERTEncoder, self).__init__()
self.token_embedding = nn.Embedding(vocab_size, num_hiddens)
self.segment_embedding = nn.Embedding(2, num_hiddens)
# 在BERT中,位置嵌入是可学习的,因此我们创建一个足够长的位置嵌入参数
self.pos_embedding = nn.Parameter(torch.randn(size=(1, max_len, num_hiddens)))
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module(f'{i}',
EncoderBlock(key_size, query_size, value_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, dropout, use_bias))
def forward(self, tokens, segments, valid_lens):
# 在以下代码段中,X的形状保持不变:(批量大小,最大序列长度,num_hiddens)
X = self.token_embedding(tokens) + self.segment_embedding(segments)
X += self.pos_embedding.data[:, :X.shape[1], :]
for blk in self.blks:
X = blk(X, valid_lens)
return X
class MaskLM(nn.Module):
"""BERT的掩蔽语言模型任务"""
def __init__(self, vocab_size, num_hiddens, num_inputs=768, **kwargs):
super(MaskLM, self).__init__()
self.mlp = nn.Sequential(nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.LayerNorm(num_hiddens),
nn.Linear(num_hiddens, vocab_size))
def forward(self, X, pred_positions):
num_pred_positions = pred_positions.shape[1]
pred_positions_id = pred_positions.reshape(-1)
batch_size = X.shape[0]
batch_id = torch.arange(0, batch_size)
batch_idx = torch.repeat_interleave(batch_id, num_pred_positions)
# 假设batch_size=2,num_pred_positions=3
# 那么batch_idx是np.array([0,0,0,1,1,1])
masked_X = X[batch_idx, pred_positions_id]
masked_X = masked_X.reshape((batch_size, num_pred_positions, -1))
mlm_Y_hat = self.mlp(masked_X)
return mlm_Y_hat
class NextSentencePred(nn.Module):
"""BERT的下一句预测任务"""
def __init__(self, num_inputs):
super(NextSentencePred, self).__init__()
self.output = nn.Linear(num_inputs, 2)
def forward(self, X):
# X的形状:(batchsize,num_hiddens)
return self.output(X)
class BERTModel(nn.Module):
"""BERT模型"""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers,
dropout, max_len=1000, key_size=768, query_size=768, value_size=768, use_bias=True,
hid_in_features=768, mlm_in_features=768, nsp_in_features=768):
super(BERTModel, self).__init__()
self.encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout, max_len,
key_size, query_size, value_size, use_bias)
self.mlm = MaskLM(vocab_size, num_hiddens, mlm_in_features)
self.hidden = nn.Sequential(nn.Linear(hid_in_features, num_hiddens), nn.Tanh())
self.nsp = NextSentencePred(nsp_in_features)
def forward(self, tokens, segments, valid_lens=None, pred_positions=None):
encoder_X = self.encoder(tokens, segments, valid_lens)
if pred_positions is not None:
mlm_Y_hat = self.mlm(encoder_X, pred_positions)
else:
mlm_Y_hat = None
# 用于下一句预测的多层感知机分类器的隐藏层,0是“<cls>”标记的索引
nsp_Y_hat = self.nsp(self.hidden(encoder_X[:, 0, :]))
return encoder_X, mlm_Y_hat, nsp_Y_hat
if __name__ == '__main__':
vocab_size, num_hiddens, ffn_num_input, ffn_num_hiddens, num_heads, num_layers = \
(1000, 768, 768, 1024, 4, 2)
norm_shape, dropout = [768], 0.2
encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout)
tokens = torch.randint(0, vocab_size, (2, 8))
segments = torch.tensor([[0, 0, 0, 0, 1, 1, 1, 1], [0, 0, 0, 1, 1, 1, 1, 1]])
enc_outputs = encoder(tokens, segments, None)
print(enc_outputs.shape)
mlm = MaskLM(vocab_size, num_hiddens)
pred_positions = torch.tensor([[1, 5, 2], [6, 1, 5]])
mlm_Y_hat = mlm(enc_outputs, pred_positions)
print(mlm_Y_hat.shape)
mlm_Y = torch.tensor([[7, 8, 9], [10, 11, 12]])
loss = nn.CrossEntropyLoss(reduction='none')
mlm_loss = loss(mlm_Y_hat.reshape((-1, vocab_size)), mlm_Y.reshape(-1))
print('mlm_loss:', mlm_loss, '\n shape:', mlm_loss.shape)
nsp = NextSentencePred(enc_outputs.shape[-1])
# NSP的输入形状:(batch_size, num_hiddens)
nsp_Y_hat = nsp(enc_outputs[:, 0, :]) # 只把<cls>(每个序列第一个词元的特征维度)的特征维度输入nsp中就行
print('nsp_Y_hat:', nsp_Y_hat, '\nnsp_Y_hat_shape:', nsp_Y_hat.shape)
nsp_Y = torch.tensor([0, 1])
nsp_loss = loss(nsp_Y_hat, nsp_Y)
print('nsp_loss:', nsp_loss, '\nnsp_loss_shape:', nsp_loss.shape)详细代码见本地 d2l-zh-pytorch/chapter_natural_language_processing。
2.6 BERT用于下游任务#
2.6.1 句子级别任务#
这类任务通常使用 [CLS] token 的向量表示整个句子的语义信息。
(1)句子分类任务(如:情感分析、自然语言推理)
输入格式:
[CLS] Sentence A [SEP] Sentence B [SEP]- 对单句任务:Sentence A 是目标句子。
- 对句对任务:Sentence A、Sentence B 是两个句子。
使用方式:
- 取 [CLS] token 的最终隐藏向量(
h_CLS)作为句子的整体表示。 - 输入一个全连接层(+Softmax)得到分类结果。
- 取 [CLS] token 的最终隐藏向量(
对应任务示例:
- MNLI(多领域自然语言推理)
- QQP(句子是否语义相同)
- SST-2(情感分类)
- QNLI(问句与句子是否相关)
2.6.2 词语级别任务#
这类任务关注句子中每个词的输出表示。
(2)序列标注任务(如:命名实体识别 NER)
输入格式:
[CLS] word1 word2 ... wordN [SEP]使用方式:
- 对每个词的最后一层隐藏向量 ,添加一个线性层(Softmax)预测标签。
- 常见输出是 BIO/BILOU 标签形式。
对应任务示例:
- CoNLL-2003 NER
2.6.3 句对关系任务#
这类任务需要判断两个句子之间的关系,使用 NSP 预训练任务 的能力。
(3)自然语言推理 / 句子关系判断
- 输入格式:
[CLS] Sentence A [SEP] Sentence B [SEP]BERT 会根据两个句子的上下文交互表示来判断它们的语义关系(例如“蕴含”、“矛盾”、“无关”)。
输出层与句子分类任务相同(用 [CLS] 的输出向量做分类)。
对应任务示例:
- MNLI, QNLI, RTE
2.6.4 机器问答任务#
(4)SQuAD 问答任务
输入格式:
[CLS] Question [SEP] Paragraph [SEP]模型输出:
- 对段落中的每个词,预测它是答案的起始位置或结束位置。
- 使用两个独立的线性层:
- Start layer → 每个词的 start probability
- End layer → 每个词的 end probability
- 选取概率最高的 (start, end) 作为答案范围。
对应任务示例:
- SQuAD v1.1 / v2.0
参考: