前言#
Generative Pre-trained Transformer(GPT)系列是由OpenAI提出的非常强大的预训练语言模型,这一系列的模型可以在非常复杂的NLP任务中取得非常惊艳的效果,例如文章生成,代码生成,机器翻译,Q&A等,而完成这些任务并不需要有监督学习进行模型微调。而对于一个新的任务,GPT仅仅需要非常少的数据便可以理解这个任务的需求并达到接近或者超过state-of-the-art的方法。
当然,如此强大的功能并不是一个简单的模型能搞定的,GPT模型的训练需要超大的训练语料,超多的模型参数以及超强的计算资源。GPT系列的模型结构秉承了不断堆叠transformer的思想,通过不断的提升训练语料的规模和质量,提升网络的参数数量来完成GPT系列的迭代更新的。GPT也证明了,通过不断的提升模型容量和语料规模,模型的能力是可以不断提升的。
1. GPT:无监督学习#
1.1 核心思想#
在GPT-1之前(和ELMo同一年),传统的NLP模型往往使用大量的数据对有监督的模型进行任务相关的模型训练,但是这种有监督学习的任务存在两个缺点:
需要大量的标注数据,高质量的标注数据往往很难获得,因为在很多任务中,图像的标签并不是唯一的或者实例标签并不存在明确的边界;
根据一个任务训练的模型很难泛化到其它任务中,这个模型只能叫做“领域专家”而不是真正的理解了NLP。
GPT-1的核心思想是,通过在超大规模无标签文本数据上进行生成式预训练,模型可以学习到丰富的世界知识和强大的语言规律。然后,对于特定的下游任务,只需要在预训练模型的基础上,通过一个简单的线性输出层 和少量的任务特定数据微调,就能将学到的通用知识迁移到新任务上,从而取得优异的效果。这种方法的优势在于避免了为每个任务从头设计模型架构。
预训练+微调范式:GPT-1开创性地将”预训练+微调“这一范式应用于NLP领域,证明其强大效力。
模型架构:它使用了Transformer的解码器 堆叠,并且只使用了掩码自注意力机制,没有使用编码器-解码器架构中的交叉注意力机制。这使得模型在生成每个词时只能关注到它左侧的上下文,是一个单向模型。
预训练目标:预训练阶段采用标准的语言模型目标,即根据前文预测下一个词,目标是最大化似然估计。
下游任务适配:针对不同的下游任务,会构造不同的输入序列格式。
1.2 GPT的训练#
GPT-1的训练分为无监督的预训练和有监督的模型微调。
1.2.1 无监督预训练#
采用标准的语言模型的目标函数,即似然函数,根据前k个词预测下一个词的概率。具体如下图所示:

1.2.2 有监督微调#
使用完整的输入序列+标签。目标函数=有监督的目标函数+λ*无监督的目标函数。具体如下图所示:

有监督微调中最终损失函数 L3 = L2 + w * L1
L1: 预训练任务的损失,即语言模型损失(根据上下文预测下一个词)。
L2: 应该是下游监督任务的损失(如分类任务的交叉熵损失)。
最终损失: L_total = L_supervised + λ * L_LM。
在微调时,模型同时优化两个目标:
- 主要目标:正确完成下游任务(如分类正确),对应损失
L_supervised。 - 辅助目标:继续保持强大的语言建模能力,对应损失
L_LM。
这里的 λ 是一个超参数,论文中通常设置为 0.5。即总损失是监督损失和语言模型损失的加权和。
1.3 GPT-1针对不同下游任务的输入/输出构造#
GPT-1论文中主要针对四大类任务设计了输入变换。其核心思想是:将所有任务都重构为模型在预训练时见过的“序列预测”任务。
输入序列由以下几种标记(Token)构成:
- Start: 序列的开始标记。
- Delim: 分隔符,用于分隔不同的句子或部分。
- Extract: 提取标记,用于某些需要提取答案的任务。
以下是四个任务的详细构造:
1. 文本分类(Classification,如情感分析)
- 输入构造:
[Start] Text [Extract] - 输出: 将Transformer最后一个时间步(即
[Extract]标记对应位置)的输出,送入一个线性层+Softmax进行分类。 - 解释: 模型读取整个文本,然后在最后输出一个分类结果。
2. 文本蕴含(Entailment,即自然语言推理)
- 输入构造:
[Start] Premise [Delim] Hypothesis [Extract] - 输出: 同样,将
[Extract]标记对应的输出送入线性分类器,判断蕴含、矛盾或中立。 - 解释: 将前提和假设用分隔符连接,让模型理解两者关系后做出判断。
3. 相似度计算(Similarity)
- 输入构造: 由于两个句子没有固定顺序,为了对称性,会构造两个输入序列。
- 序列1:
[Start] Text1 [Delim] Text2 [Extract] - 序列2:
[Start] Text2 [Delim] Text1 [Extract]
- 序列1:
- 输出: 将两个输入序列在
[Extract]标记处的输出按元素相加,然后将结果送入线性分类器预测相似度。 - 解释: 通过两种顺序的输入,让模型更好地理解句子间的对称相似关系。
4. 多项选择问答(Multiple Choice QA)
输入构造: 对于每个候选答案,都构造一个输入序列。
对于每个
(Context, Question, Answer_i),构造:[Start] Context [Delim] Question [Delim] Answer_i [Extract]输出: 对每个候选答案对应的序列,计算
[Extract]标记处的输出,并通过一个线性层得到一个分数。最后对所有候选答案的分数进行Softmax归一化,选择概率最高的答案。解释: 将问题和每个候选答案组合成一个新的“文本”,让模型判断哪个组合最通顺、最合理。
以上部分的解释如下图所示: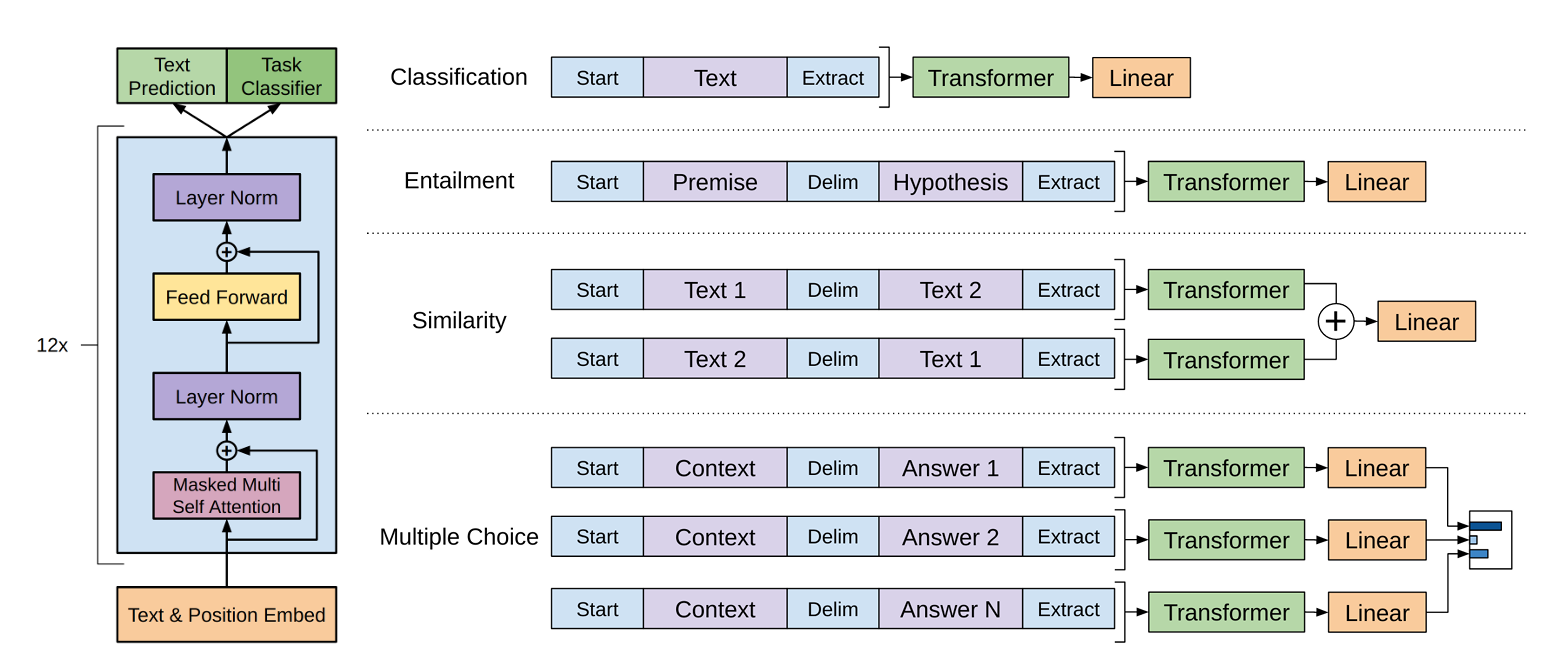
1.4 GPT数据集#
GPT-1使用了BooksCorpus数据集。这个数据集包含7000本没有发布的书籍。作者选这个数据集的原因有二:
- 数据集拥有更长的上下文依赖关系,使得模型能学得更长期的依赖关系;
- 这些书籍因为没有发布,所以很难在下游数据集上见到,更能验证模型的泛化能力。
1.5 GPT模型参数#
1.5.1预训练阶段#
- 模型架构: 12层Transformer解码器堆叠。
- 注意力头数: 12个。
- 隐藏层维度: 768维。
- FFN层中间维度: 3072维(4倍隐藏层维度)。
- 激活函数: GELU。
- 参数总量: 约1.17亿 (117M)。
- 词表大小: 40,000 Byte Pair Encoding (BPE) 子词单元。
- 位置编码: 学习式的位置编码。
- 预训练数据: BooksCorpus数据集(约7,000本未出版的书籍)。
- 优化器: Adam。
- Batch Size: 64个随机、连续的文本序列,每个序列长度为512个token。
- 学习率为
2.5e-4,训练epoch为 100;模型参数数量为 1.17亿。
1.5.2 有监督微调阶段#
- 模型主体架构和参数: 从预训练模型中初始化。
- 新增参数: 仅在顶部为每个任务添加一个线性分类层。
- 超参数: 大部分超参数与预训练阶段相同。训练的epoch为3 ,学习率为
6.25e-5。 - 损失函数权重 λ: 论文中在大部分任务上设置为 0.5。
1.6 实验结果#
在有监督学习的12个任务中,GPT-1在9个任务上的表现超过了state-of-the-art的模型。在没有见过数据的zero-shot任务中,GPT-1的模型要比基于LSTM的模型稳定,且随着训练次数的增加,GPT-1的性能也逐渐提升,表明GPT-1有非常强的泛化能力,能够用到和有监督任务无关的其它NLP任务中。GPT-1证明了transformer对学习词向量的强大能力,在GPT-1得到的词向量基础上进行下游任务的学习,能够让下游任务取得更好的泛化能力。对于下游任务的训练,GPT-1往往只需要简单的微调便能取得非常好的效果。
GPT-1在未经微调的任务上虽然也有一定效果,但是其泛化能力远远低于经过微调的有监督任务,说明了GPT-1只是一个简单的领域专家,而非通用的语言学家。
1.7 GPT与BERT区别#
| 特性 | GPT-1 | BERT |
|---|---|---|
| 核心架构 | Transformer 解码器 | Transformer 编码器 |
| 注意力机制 | 单向 / 因果。只能关注左侧上下文,采用掩码自注意力。 | 双向。可以同时关注左右两侧的上下文,采用完全自注意力。 |
| 预训练目标 | 自回归语言模型。目标是根据前文预测下一个词。 | 去噪自编码。主要目标是 Masked Language Model,即随机遮盖词并预测它。此外还有 Next Sentence Prediction 任务。 |
| 模型能力倾向 | 生成任务。因其单向特性,天然适合文本生成、对话等。 | 理解任务。因其双向特性,在文本分类、阅读理解、实体识别等理解类任务上表现更强。 |
| 数据流 | 从左到右的序列,适合序列生成。 | 一次性看到整个句子,适合整体理解。 |
| 微调策略 | 在总损失中引入语言模型损失作为辅助 (L_total = L_task + λ * L_LM)。 | 通常只优化下游任务损失 (L_task),不使用MLM损失作为辅助。 |
| 代表性参数 | 117M 参数 (GPT-1 base) | BERT_Base: 110M 参数 (12层, 768隐层, 12头) BERT_Large: 340M 参数 (24层, 1024隐层, 16头) |
| 哲学差异 | “通过生成来理解”。认为一个能够完美预测下一个词的模型,必然已经深刻理解了语言。 | “通过完形填空来理解”。认为通过恢复被破坏的文本,可以学习到词语和句子间的深层关系。 |
3. GPT-2:多任务学习#
2.1 核心思想#
GPT-2 的提出是对 GPT-1 “预训练+微调”范式的一次突破。
在 GPT-1 中,模型先在大规模语料上进行语言模型预训练,再通过有监督的微调适配具体下游任务。这种方式虽然有效,但存在两个明显弊端:
- 任务依赖性强:每个任务都需要收集带标签的数据集,并针对性地微调模型。
- 计算开销大:微调过程不仅耗时,还需要大量计算资源,这使得跨领域泛化能力受限。换句话说,GPT-1 并不是“真正的通用智能”,而是一种带有监督信号的领域自适应。
GPT-2 的核心论点是:当模型容量足够大且训练语料足够广泛、多样时,一个纯粹的自回归语言模型通过学习文本续写的条件概率,就能够在统计意义上覆盖并完成许多传统上需要监督学习解决的下游任务,而无需对每个任务单独微调。换言之,许多有监督任务(翻译、摘要、问答等)只是自然语料中出现的特定文本格式或“任务范式”的子集;模型在大规模语料中见过类似的任务描述与示例后,就能通过在推理时给出自然语言提示(prompt)来实现 zero-shot 的任务执行。为保证 zero-shot 的有效性,提示应尽量与预训练时看到的自然语言形式一致(而不是包含训练时未见过的特殊开始/结束符号或人工结构化标记),例如用“Translate to French: …”或“Summary: …”这样自然的任务描述来引导模型续写。
Zero-Shot 学习(零样本学习):在推理阶段,不再依赖标注数据和参数更新,只需提供一个描述任务的 Prompt。由于模型在训练语料中已经见过各种任务的自然描述,它能够直接“类比”完成这些任务。例如:
- 在训练中见过“文章:… 总结:…” → 学会摘要。
- 见过“English: … French: …” → 学会翻译。
- 见过“问题:… 答案:…” → 学会问答。 因此,在推理时,只要用类似的提示语构造输入,模型便能在 Zero-Shot 设定下给出合理的输出。
综上:GPT-1 依赖“预训练+微调”,导致对任务和标注数据高度依赖;GPT-2 则将所有任务视为条件化的语言建模问题,通过设计自然语言的 prompt 与示例在同一模型中复用预训练得到的能力,从而降低对标注数据和微调次数的依赖,实现更好的可扩展性和即时适应能力。其有效性依赖于模型容量与语料覆盖度——当模型和数据足够大时,训练集中自然存在的“任务格式”足以让模型在推理阶段通过提示直接完成许多监督任务。
2.2 GPT-2数据集#
GPT-2的文章取自于Reddit上高赞的文章,命名为 WebText ,它是一个超大、超多样化的数据集,包含了从互联网上爬取的数千万个网页,涵盖了新闻、论坛、书籍、代码、问答等各种文体和内容。正是这种 “任务多样性”被隐式地编码在了训练数据中,才使得模型学会了在Zero-Shot设置下响应各种提示。
注意:GPT-2的论文主要推崇和验证的是Zero-Shot能力。但需要注意的是,GPT-2模型同样可以像GPT-1一样,通过在有标签数据上微调来获得特定任务的极致性能。论文中在部分任务上也给出了微调后的结果作为对比。
2.3 GPT-2模型参数#
GPT-2的一个显著特点是其可扩展性。为了探索模型规模与性能的关系,OpenAI发布了四个不同规模的版本。
| 模型名称 | 层数 | 隐藏层维度 | 注意力头数 | 参数量 |
|---|---|---|---|---|
| GPT-2 Small | 12 | 768 | 12 | 124 Million |
| GPT-2 Medium | 24 | 1024 | 16 | 355 Million |
| GPT-2 Large | 36 | 1280 | 20 | 774 Million |
| GPT-2 XL | 48 | 1600 | 25 | ~1.5 Billion |
2.4 实验结果#
在8个语言模型任务中,仅仅通过zero-shot学习,GPT-2就有7个超过了state-of-the-art的方法;
在“Children’s Book Test”数据集上的命名实体识别任务中,GPT-2超过了state-of-the-art的方法约7%;
“LAMBADA”是测试模型捕捉长期依赖的能力的数据集,GPT-2将困惑度从99.8降到了8.6;
在阅读理解数据中,GPT-2超过了4个baseline模型中的三个;
在法译英任务中,GPT-2在zero-shot学习的基础上,超过了大多数的无监督方法,但是比有监督的state-of-the-art模型要差;
GPT-2在文本总结的表现不理想,但是它的效果也和有监督的模型非常接近。
2.5 GPT-2与GPT-1对比和区别#
| 特性 | GPT-1 | GPT-2 |
|---|---|---|
| 核心目标 | 验证“预训练+微调”范式的有效性。 | 验证大规模无监督预训练能否直接实现Zero-Shot多任务学习。 |
| 训练数据 | BooksCorpus(约7,000本书,4.6GB)。 | WebText(约800万网页,40GB)。数据量更大、来源更广、内容更多样。 |
| 模型规模 | 单一模型,117M 参数。 | 多个规模的模型,从124M到1.5B,核心是探索Scaling Law。 |
| 上下文长度 | 512 tokens。 | 1024 tokens。 |
| 技术改进 | 标准的Transformer解码器架构。 | 移除了微调阶段的辅助LM损失;调整了层归一化的位置;改进了初始化方法。 |
| 任务处理方式 | 任务特定微调。需要为不同任务设计输入变换和添加线性分类头。 | 任务无关的Zero-Shot。通过提示(Prompt) 来引导模型,无需修改模型架构或参数。 |
| 哲学思想 | “通过生成式预训练来获得一个强大的、可迁移的特征提取器”。 | “一个通用的、任务无关的系统,可以通过条件生成来完成任何任务”。 |
| 影响 | 与BERT一起,确立了预训练+微调作为NLP新范式。 | 提出了“万物皆可生成”和“Prompt即指令”的雏形,为GPT-3和后来的大语言模型(LLM)革命铺平了道路。 |
3. GPT-3:上下文学习#
3.1 核心思想#
在 GPT-2 中,研究者已经证明了大规模语言模型具备 Zero-Shot 学习能力,即不经过任务特定的微调,仅依赖合适的 Prompt 也能完成部分任务。然而,GPT-2 的参数规模(15 亿)仍然有限,其在复杂任务上的表现不够理想。基于此,OpenAI 在 GPT-3 中进一步提出了“规模定律(Scaling Law):当模型规模、数据量和计算量不断提升时,模型在语言理解与生成上的能力会持续增长,而无需改变架构。”,并通过构建 1750 亿参数的超大模型,探索了更高层次的通用性。
GPT-3 的核心思想可以概括为以下几点:
极大规模化: GPT-3 的最大特点是采用了前所未有的参数规模。研究者发现,当模型规模、数据量和算力不断提升时,模型的语言理解与生成能力会持续增强。这一发现表明,单纯依靠规模扩展而不改变模型架构,依旧能够显著提升模型的泛化性能。
上下文学习(In-Context Learning): GPT-3 在推理阶段展现出了一种新的学习方式,即通过输入中的上下文提示来完成任务,而无需更新参数。例如,在文本分类任务中,只需在输入中提供少量“输入—输出”的示例,模型便能够类比学习并生成符合要求的结果。这表明 GPT-3 能够将学习过程转移到推理阶段的上下文中。
**元学习(Meta-Learning):**在上下文学习的基础上,GPT-3 展现出类似 元学习 的特征。传统机器学习在面对新任务时需要显式训练,而 GPT-3 仅依赖少量示例就能快速适配任务。这种能力表现为“学习如何学习”,意味着模型能够通过 Prompt 灵活切换任务,而不需要参数层面的更新。
**Prompt 驱动范式的统一:**GPT-3 将不同任务统一为 条件文本生成问题,差异仅体现在 Prompt 的设计上:
- 在 Zero-Shot 模式下,直接使用自然语言指令;
- 在 One-Shot 模式下,在输入中加入一个示例;
- 在 Few-Shot 模式下,输入多个示例(通常为10-100个),模拟训练过程。
这种方式使模型能够在无需针对性微调的前提下,完成多种自然语言处理任务。下图展示了GPT中Zero-Shot、One-Shot、Few-Shot以及Fine-tuning的区别。
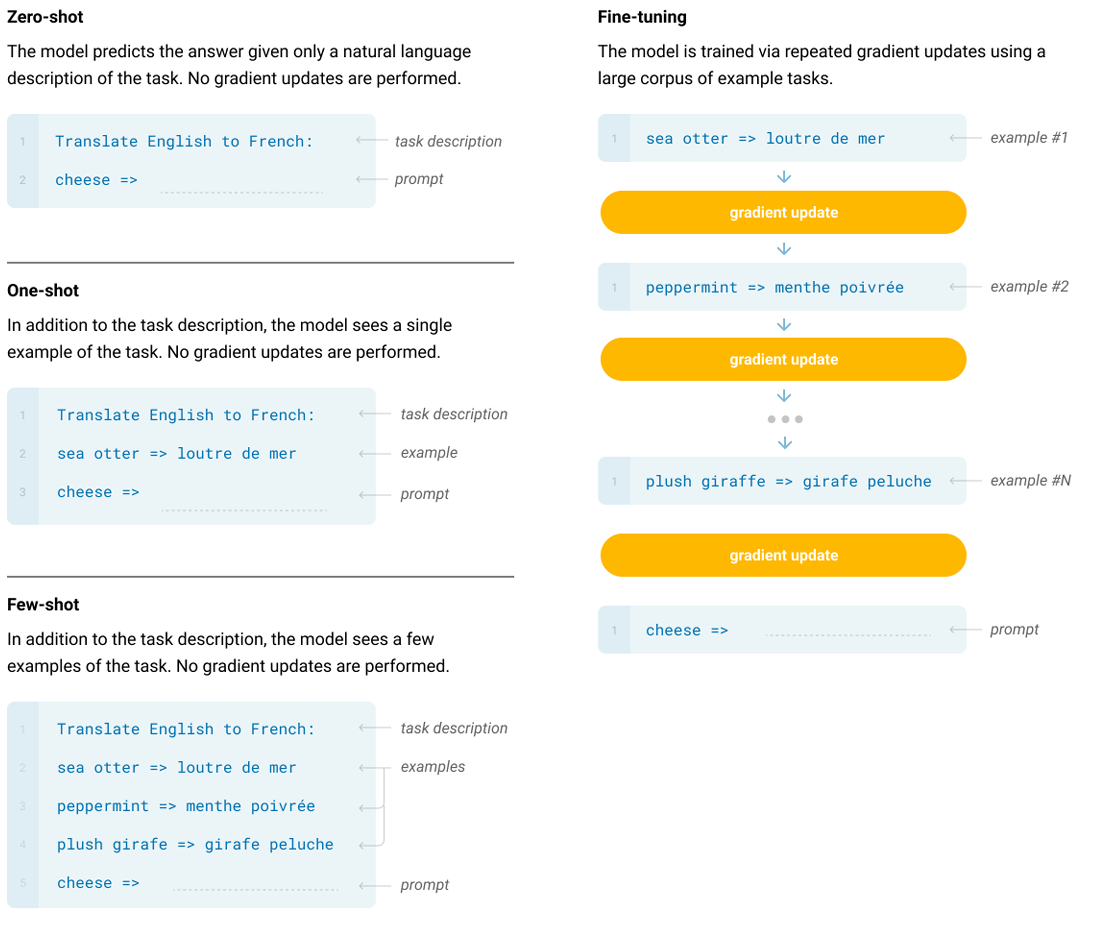
此外,GPT-3 展现出的 元学习能力 表明,它可以通过少量示例快速适应新任务,具备了初步的“学习如何学习”的特征。这使得 GPT-3 不再仅仅是一个语言建模工具,而是演变为一个灵活的任务适配器。
最后,GPT-3 通过 Zero-Shot、One-Shot 与 Few-Shot 等 Prompting 方式,统一了不同任务的执行逻辑,真正实现了**“任务即语言建模”**。因此,GPT-3 相较于 GPT-2,不仅在规模上实现了跨越,更在认知能力层面迈出了通向通用人工智能的重要一步。
3.2 GPT-3数据集#
GPT-3使用了比GPT-2的WebText更大、更多样化的混合数据集。其来源和比例如下:
| 数据集来源 | 权重 | 描述 |
|---|---|---|
| Common Crawl (过滤后) | 60% | 核心数据源,进行了严格的质量过滤(基于与高质量语料的相似度)和去重。 |
| WebText2 (GPT-2的数据扩展版) | 22% | 高质量的内部数据集。 |
| Books1 | 8% | 两个书籍语料库之一。 |
| Books2 | 8% | 两个书籍语料库之一,质量更高。 |
| Wikipedia | 3% | 仅英文维基百科的文本部分。 |
总训练数据量约570GB的纯文本,包含近万亿个单词。
3.3 GPT-3模型参数#
GPT-3的架构与GPT-2基本相同,仍然是仅解码器的Transformer模型。其所有的改进几乎都来自于 “放大”。
- 参数规模: 1750亿(175 Billion)参数。这比之前最大的稠密模型(如Turing-NLG的17B)大了一个数量级。
- 模型尺寸: 为了达到175B参数,OpenAI训练了8种不同规模的模型来研究缩放定律,其中最大的GPT-3配置如下:
- 层数: 96
- 注意力头数: 96
- 隐藏层维度: 12288
- 批次大小: 3.2M个token(动态调整)
- 上下文窗口: 2048个token(比GPT-2又翻倍)
- 关键技术细节:
- 为了在如此大的模型下节省内存,采用了模型并行技术。
- 在自注意力层中使用了交替的稠密和局部带状稀疏注意力模式,以在某些层中高效处理长序列
3.4 实验结果#
仅仅用惊艳很难描述GPT-3的优秀表现。首先,在大量的语言模型数据集中,GPT-3超过了绝大多数的zero-shot或者few-shot的state-of-the-art方法。另外GPT-3在很多复杂的NLP任务中也超过了fine-tune之后的state-of-the-art方法,例如闭卷问答,模式解析,机器翻译等。除了这些传统的NLP任务,GPT-3在一些其他的领域也取得了非常震惊的效果,例如进行数学加法,文章生成,编写代码等。
3.5 GPT-2与GPT-3的对比#
| 特性 | GPT-2 | GPT-3 |
|---|---|---|
| 核心目标 | 验证Zero-Shot多任务学习的可行性。 | 验证超大规模模型下的Few-Shot In-Context Learning能否达到或超越微调模型的水平。 |
| 关键能力 | Zero-Shot | Few-Shot, One-Shot, Zero-Shot,且Few-Shot是其主要优势。 |
| 哲学思想 | “一个通用的任务无关系统”。 | “一个通过预训练完成了元学习的通用系统,可通过上下文快速适应新任务”。 |
| 模型规模 | 最大 1.5B 参数。 | 175B 参数,两个数量级的差距。 |
| 训练数据 | WebText (~40GB)。 | 混合高质量数据集,~570GB,规模更大、清洗更严格。 |
| 上下文长度 | 1024 tokens。 | 2048 tokens。 |
| 计算成本 | 相对较低。 | 极其昂贵,训练一次需数千PetaFLOPs-day的计算量。 |
| 评估方式 | 主要评估Zero-Shot,并与微调基线对比。 | 系统性地评估Few-Shot, One-Shot, Zero-Shot,并与微调的SOTA模型直接竞争。 |
| 涌现能力 | 展示了有希望的Zero-Shot潜力。 | 展示了惊人的涌现能力,如进行数学运算、编写复杂的代码、理解抽象概念等,这些能力在较小模型上几乎不存在。 |
| 影响与局限 | 为LLM和Prompting思想铺平了道路。 | 真正开启了大语言模型时代。证明了“缩放定律”的惊人潜力,同时也暴露了模型的局限性(如事实幻觉、重复训练数据偏见等)。 |
总结:GPT-3不是一次算法上的革命,而是一次工程和理念上的极致探索。它将以GPT为代表的“生成式预训练”道路推向了当时的顶峰,并雄辩地证明:
- 规模本身就是一种能力:当模型大到一定程度时,会涌现出小模型不具备的In-Context Learning等高级能力。
- 范式转移:对于许多NLP任务,收集大量标注数据并微调模型的传统范式,可能不再是唯一的最佳路径。通过精心设计的Prompt,直接利用大模型的内部知识成为可能。
GPT-3的成功直接催生了后来的Codex、InstructGPT和ChatGPT,奠定了当前AI浪潮的基础。
4. 总结#
GPT系列从1到3,通通采用的是Transformer架构,可以说模型结构并没有创新性的设计。在微软的资金支持下,这更像是一场赤裸裸的炫富:1750亿的参数,31个分工明确的作者,超强算力的计算机( 285000个CPU, 10000个GPU),1200万的训练费用,45TB的训练数据(维基百科的全部数据只相当于其中的0.6% )。这种规模的模型是一般中小企业无法承受的,而个人花费巨金配置的单卡机器也就只能做做微调或者打打游戏了。甚至在训练GPT-3时出现了一个bug,OpenAI自己也没有资金重新训练了。
读懂了GPT-3的原理,相信我们就能客观的看待媒体上对GPT-3的过分神话了。GPT-3的本质还是通过海量的参数学习海量的数据,然后依赖Transformer强大的拟合能力使得模型能够收敛。基于这个原因,GPT-3学到的模型分布也很难摆脱这个数据集的分布情况。得益于庞大的数据集,GPT-3可以完成一些令人感到惊喜的任务,但是GPT-3也不是万能的,对于一些明显不在这个分布或者和这个分布有冲突的任务来说,GPT-3还是无能为力的。例如通过目前的测试来看,GPT-3还有很多缺点的:
- 对于一些命题没有意义的问题,GPT-3不会判断命题有效与否,而是拟合一个没有意义的答案出来;
- 由于40TB海量数据的存在,很难保证GPT-3生成的文章不包含一些非常敏感的内容,例如种族歧视,性别歧视,宗教偏见等;
- 受限于transformer的建模能力,GPT-3并不能保证生成的一篇长文章或者一本书籍的连贯性,存在下文不停重复上文的问题。
OpenAI的CEO也发Twitter说“The GPT-3 hype is way too much. It’s impressive (thanks for the nice compliments!) but it still has serious weaknesses and sometimes makes very silly mistakes. AI is going to change the world, but GPT-3 is just a very early gimpse. We have a lot still to figure out.”
GPT-3对AI领域的影响无疑是深远的,如此强大性能的语言模型的提出,为下游各种类型的NLP任务提供了非常优秀的词向量模型,在此基础上必将落地更多有趣的AI应用。近年来,硬件的性能在飞速发展,而算法的研究似乎遇见了瓶颈,GPT-3给冷清的AI领域注入了一剂强心剂,告诉各大硬件厂商它们的工作还要加油,只要算力足够强,AI的性能还有不断提升的上界。
同时GPT-3如此高昂的计算代价也引发了一些关于AI领域垄断的一些担心,对于如此高的算力要求,中小企业是否有能力负担的起,或者对于这些企业来说,是否有必要花这么多钱就训练一个词向量模型。长此以往,恐怕会形成AI巨头对算力要求高的算法的技术垄断。
参考: